Overview of the technical foundations of language models in 2025, from attention mechanisms to architectural innovations that make LLMs efficient and powerful.
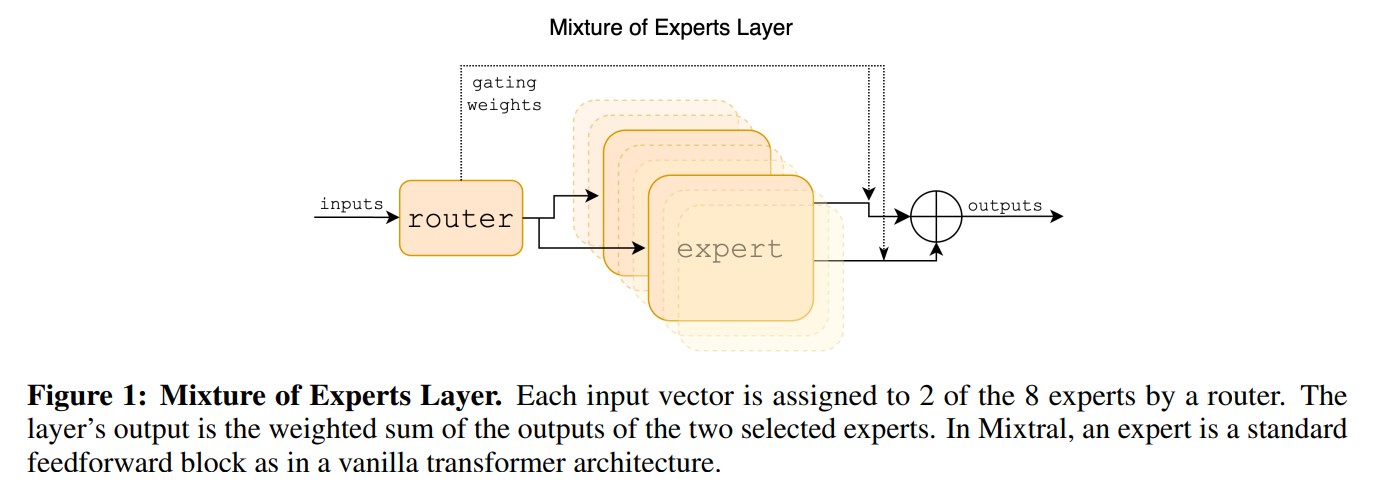
Unpacking Mixture-of-Experts (MoE) in LLMs: A Foundational Dive
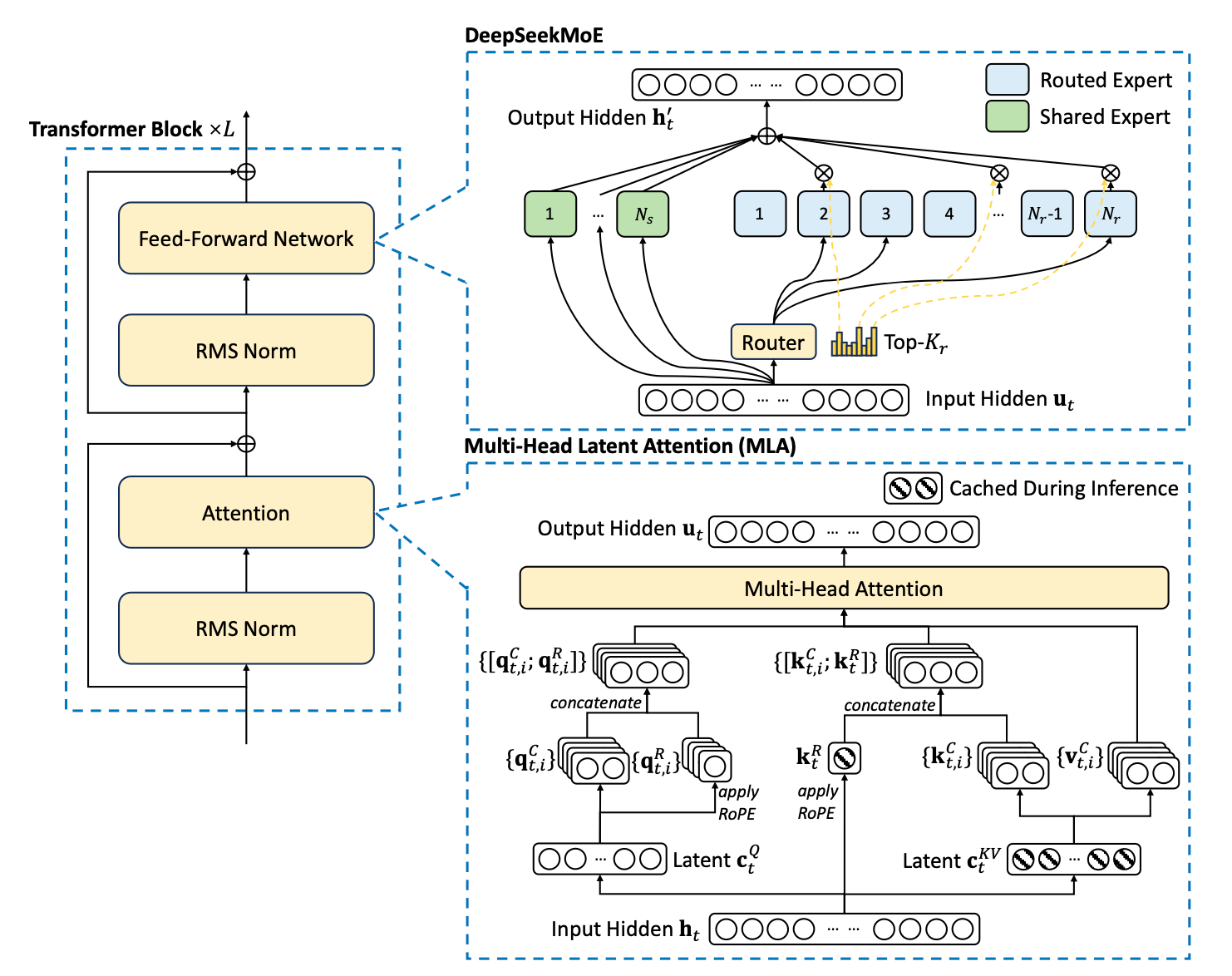
This blog post demystifies Mixture-of-Experts (MoE) layers, a key innovation for scaling Large Language Models efficiently. We’ll trace its origins, delve into the mathematical underpinnings, and build a foundational MoE block in PyTorch, mirroring the architecture from its initial conception.