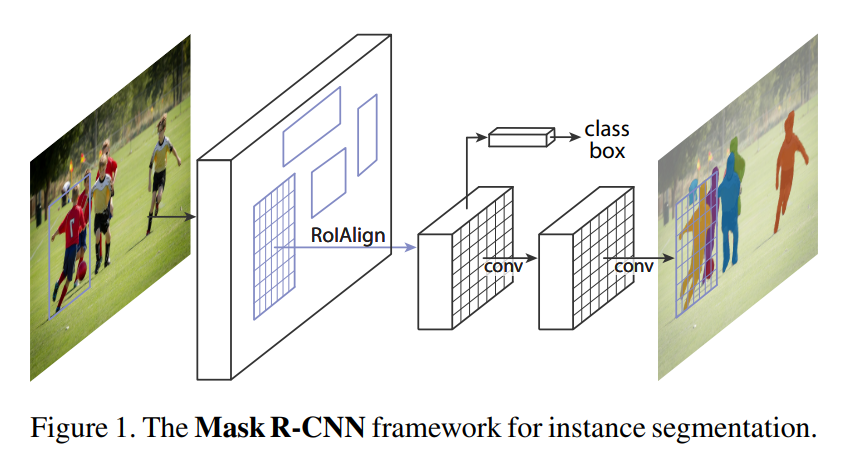
Mask R-CNN: Extending Object Detection to Instance Segmentation
Mask R-CNN elegantly extends Faster R-CNN by adding a mask prediction branch, achieving state-of-the-art instance segmentation through simple yet effective architectural choices.
Mask R-CNN elegantly extends Faster R-CNN by adding a mask prediction branch, achieving state-of-the-art instance segmentation through simple yet effective architectural choices.
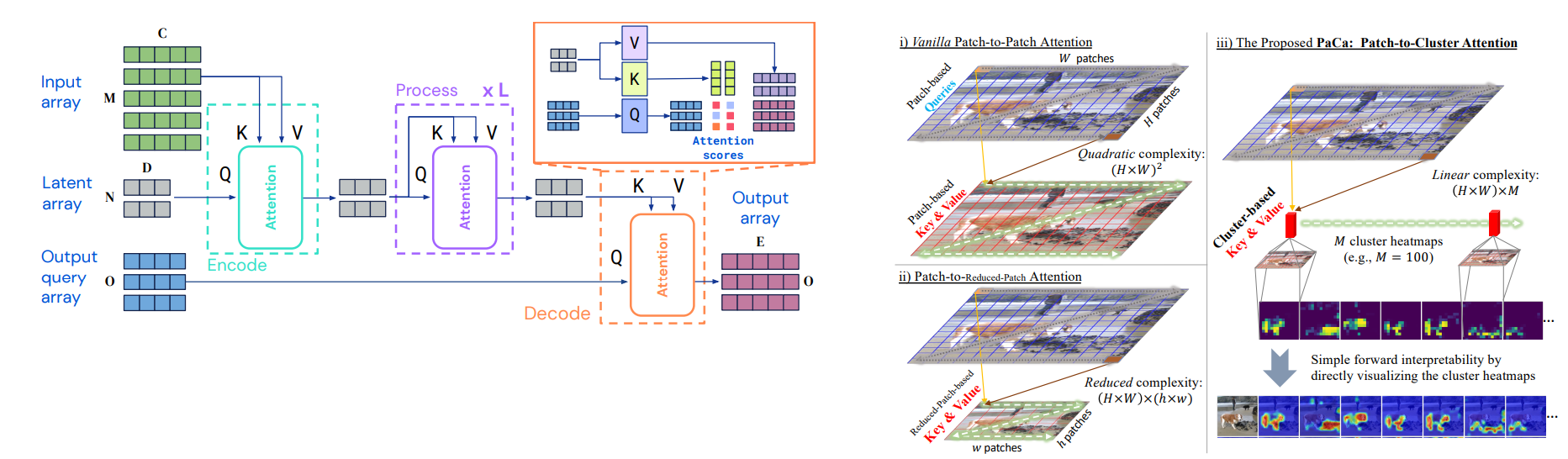
A deep dive into two novel architectures, Perceiver IO and PaCa-ViT, that break the O(N^2) barrier in Transformers, enabling them to process massive inputs efficiently.
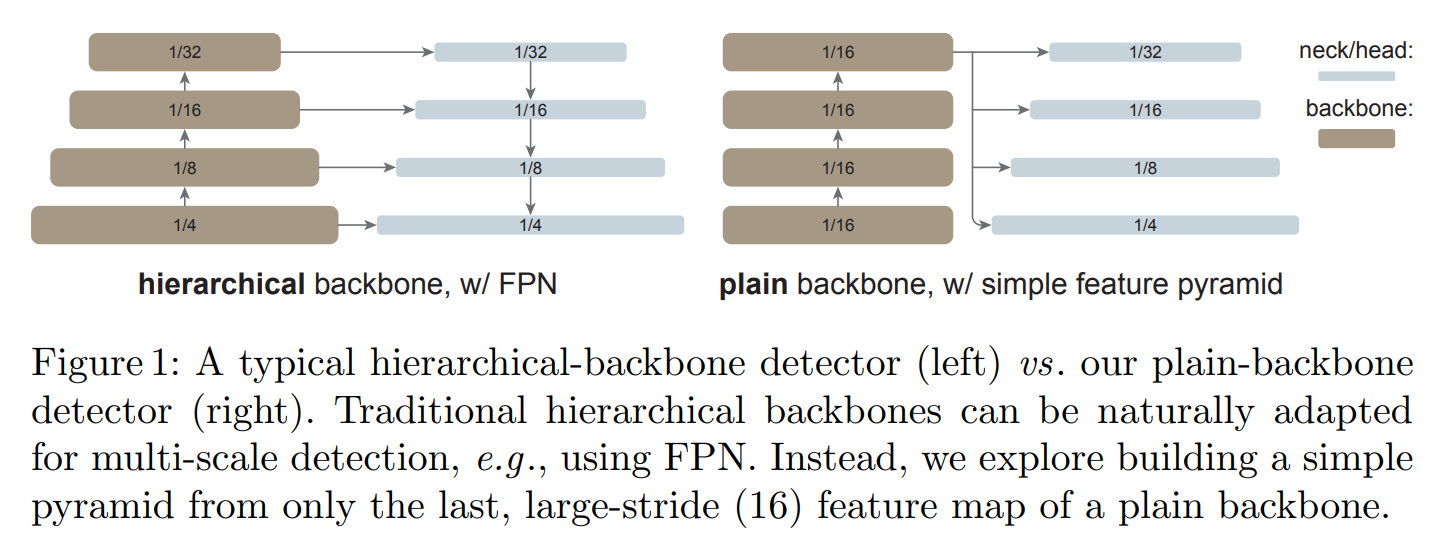
ViTDet demonstrates that plain, non-hierarchical Vision Transformers can compete with hierarchical backbones for object detection through simple adaptations.
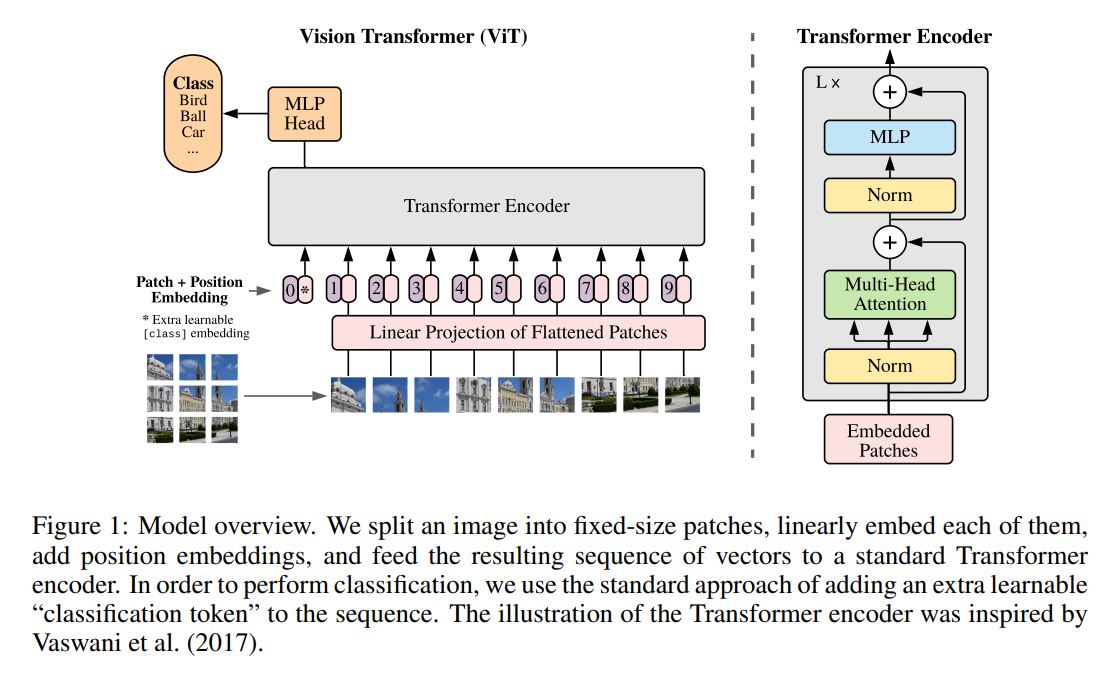
An in-depth look at ‘An Image is Worth 16x16 Words,’ the paper that introduced the pure Vision Transformer, its architecture, novelty, limitations, and how modern models like Swin Transformer evolved from it.
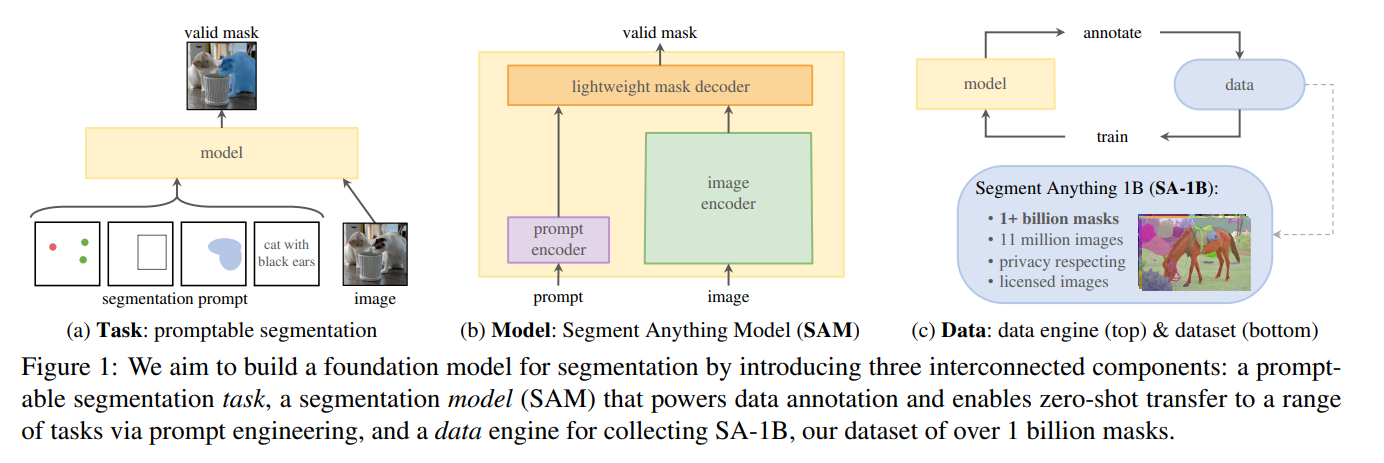
Meta’s Segment Anything Model (SAM 1) delivers a wide variety of predictsion, detections, and segmentations with a remarkable accuracy. Part 1 from 3.
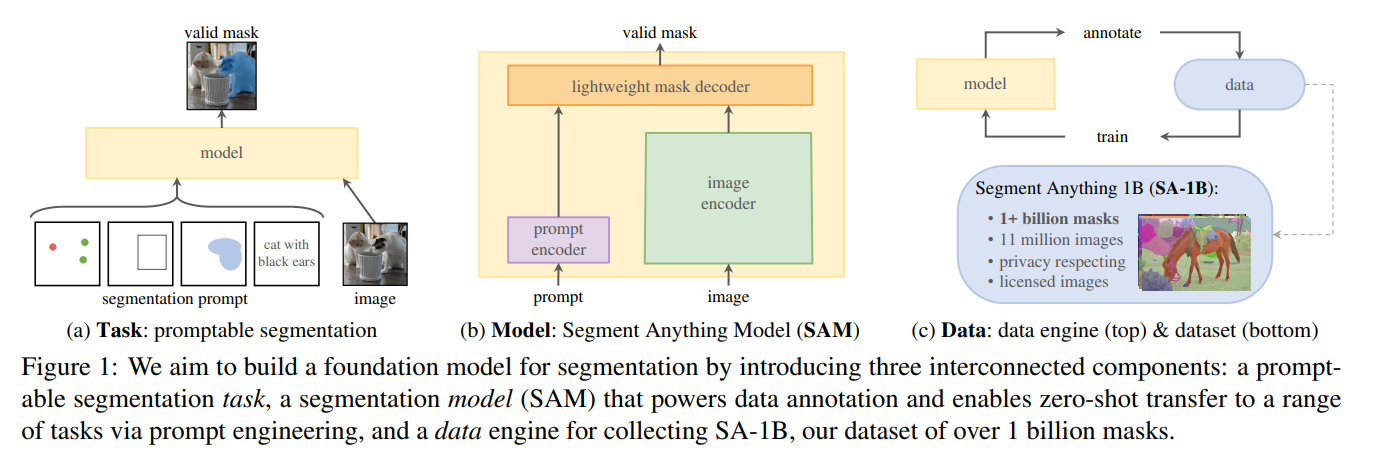
Meta’s Segment Anything Model (SAM 1) delivers a wide variety of predictsion, detections, and segmentations with a remarkable accuracy. Part 2 from 3.

A brief technical comparison of the five most advanced camouflaged object detection methods in 2025, including ZoomNeXt, HGINet, RAG-SEG, MoQT, and SPEGNet, with detailed analysis of their architectures.
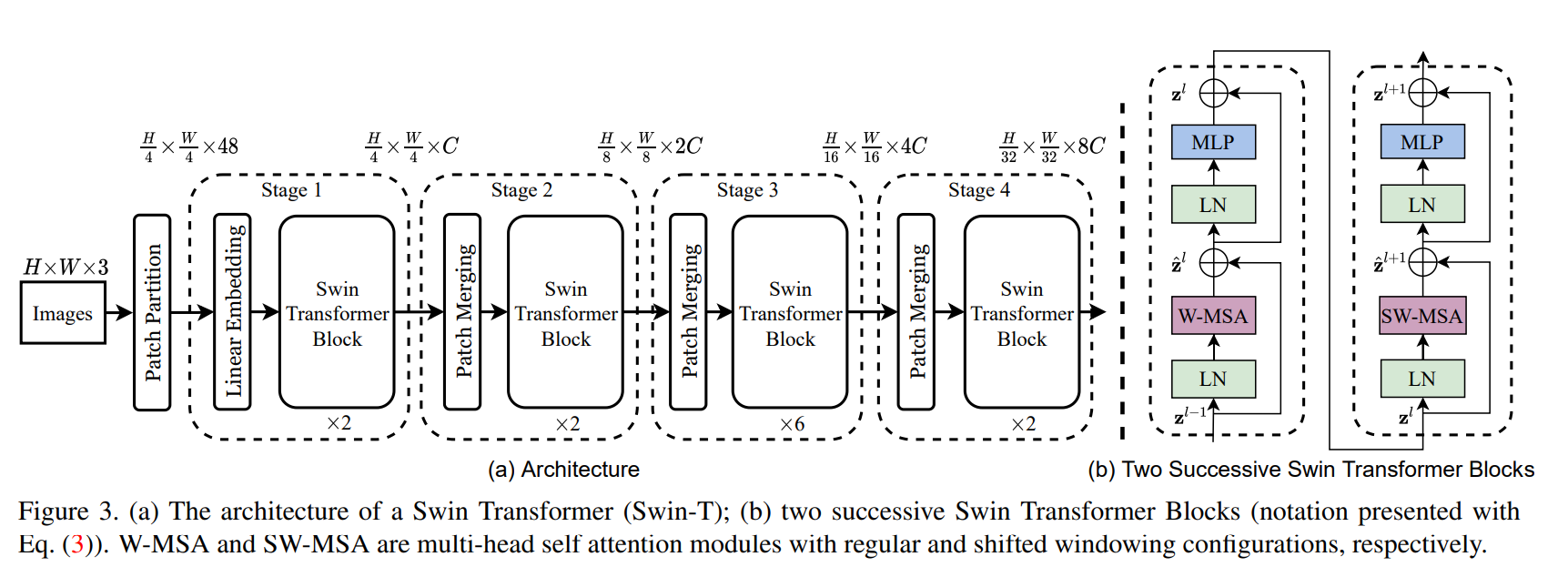
This post provides a minimal PyTorch implementation of Swin Transformer for a simple image classification.
This post details the machine learning strategy—including multi-task learning, transfer learning, and heatmap-based landmark detection—used to build an AI system that automates bone age assessment from X-ray images, achieving high accuracy with limited medical data.