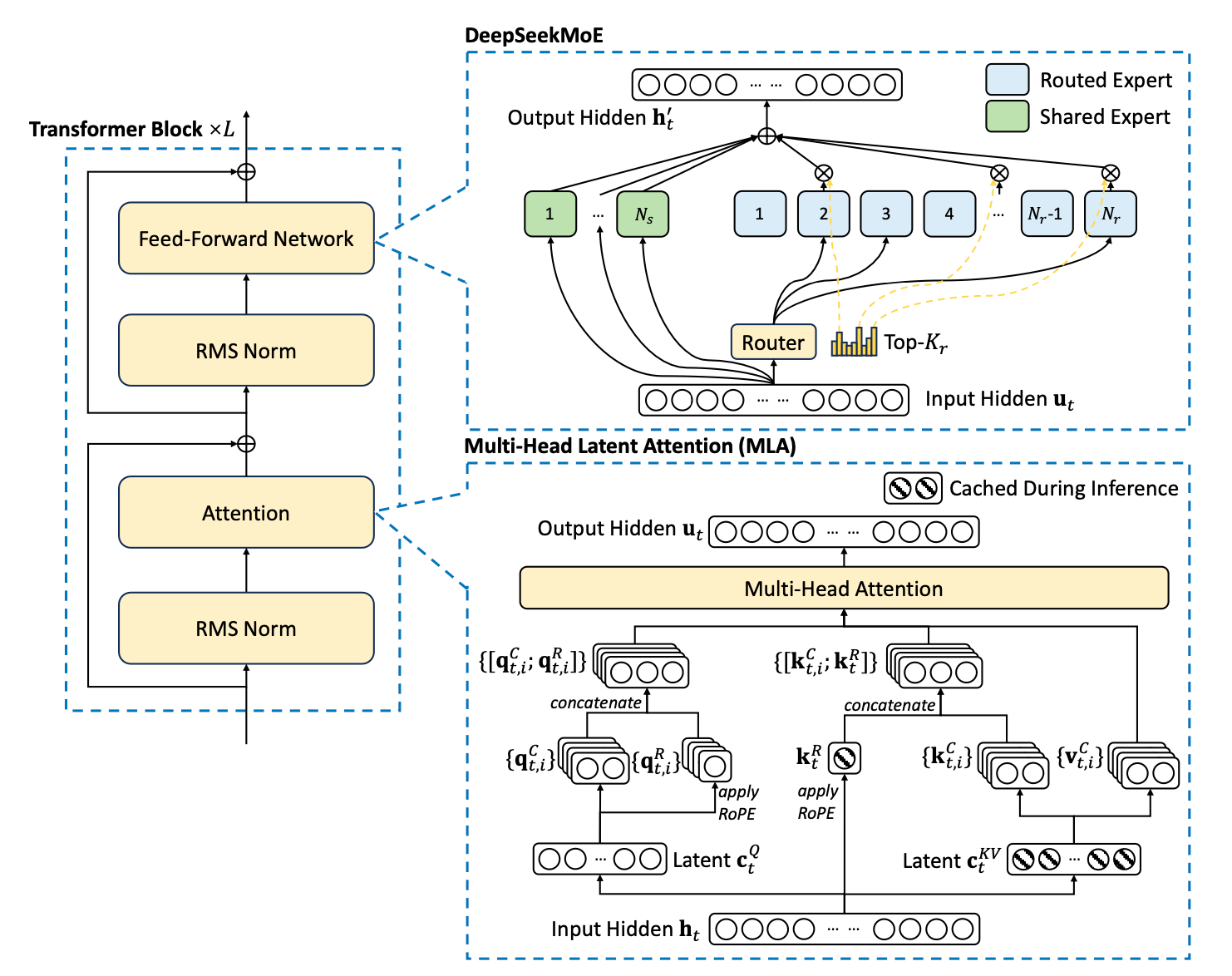
Multi-head Latent Attention (MLA): Making Transformers More Efficient
This blog post explains Multi-head Latent Attention (MLA) and provides minimal working code in pytorch.
This blog post explains Multi-head Latent Attention (MLA) and provides minimal working code in pytorch.
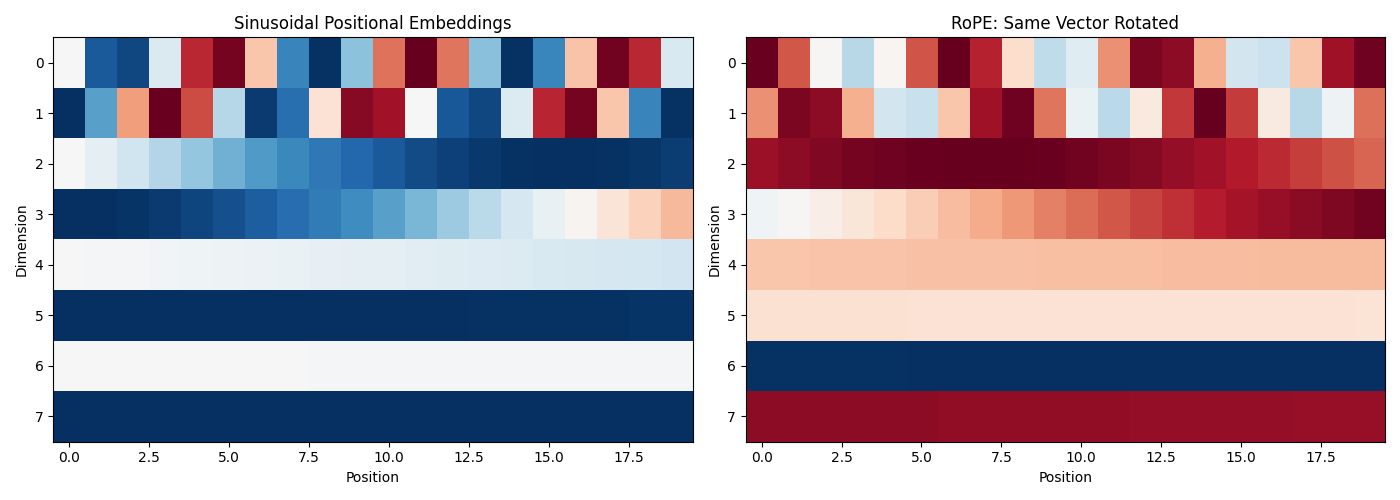
This blog post explains RoPE in simple terms, showing how it differs from sinusoidal embeddings and why it’s become the standard for modern language models.