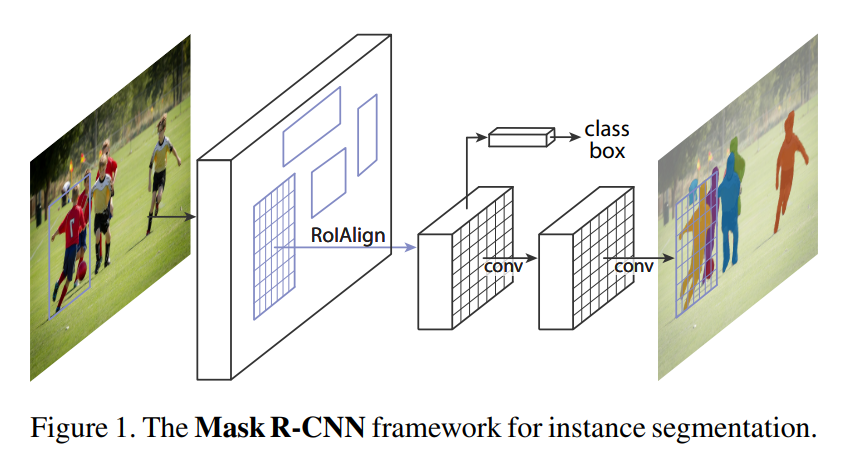
Mask R-CNN: Extending Object Detection to Instance Segmentation
Mask R-CNN elegantly extends Faster R-CNN by adding a mask prediction branch, achieving state-of-the-art instance segmentation through simple yet effective architectural choices.
Mask R-CNN elegantly extends Faster R-CNN by adding a mask prediction branch, achieving state-of-the-art instance segmentation through simple yet effective architectural choices.
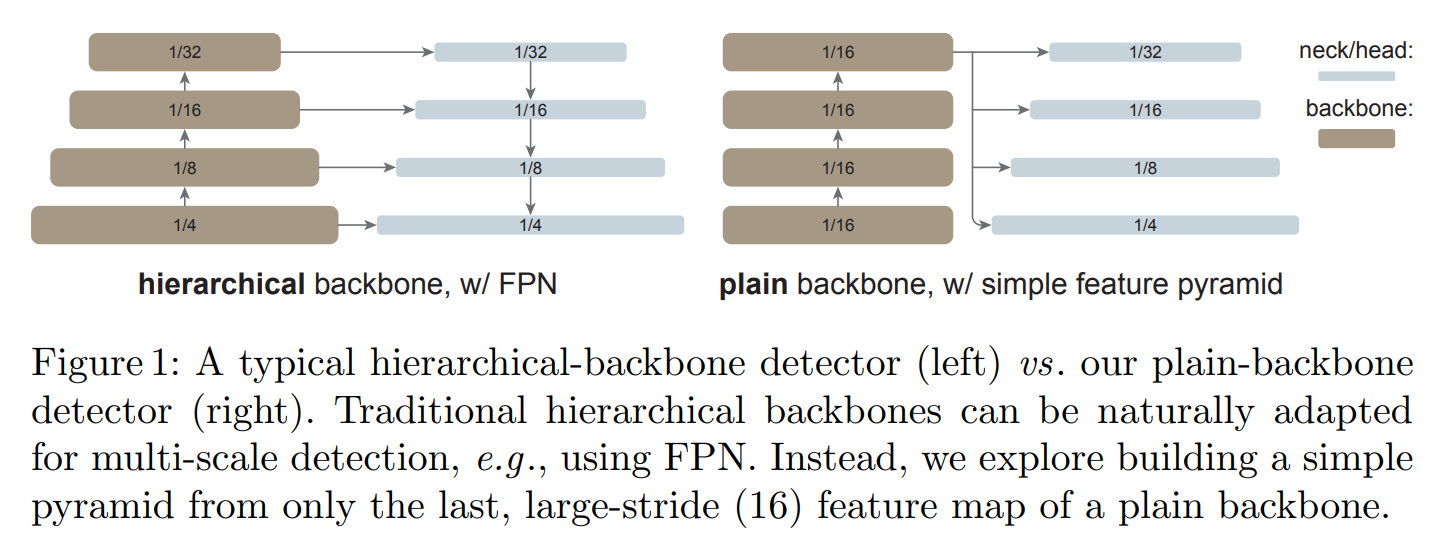
ViTDet demonstrates that plain, non-hierarchical Vision Transformers can compete with hierarchical backbones for object detection through simple adaptations.

A brief technical comparison of the five most advanced camouflaged object detection methods in 2025, including ZoomNeXt, HGINet, RAG-SEG, MoQT, and SPEGNet, with detailed analysis of their architectures.