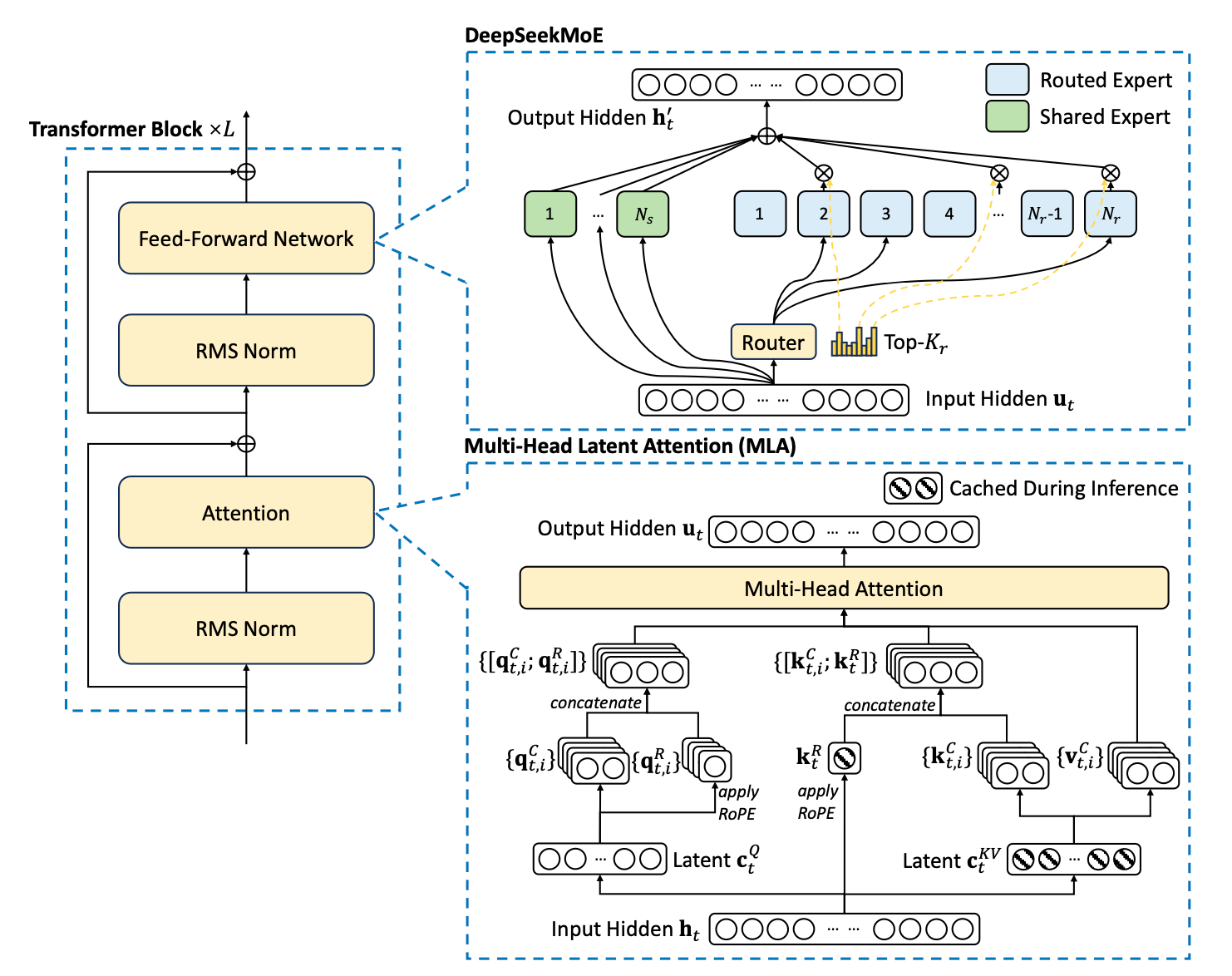
Multi-head Latent Attention (MLA): Making Transformers More Efficient
This blog post explains Multi-head Latent Attention (MLA) and provides minimal working code in pytorch.
This blog post explains Multi-head Latent Attention (MLA) and provides minimal working code in pytorch.