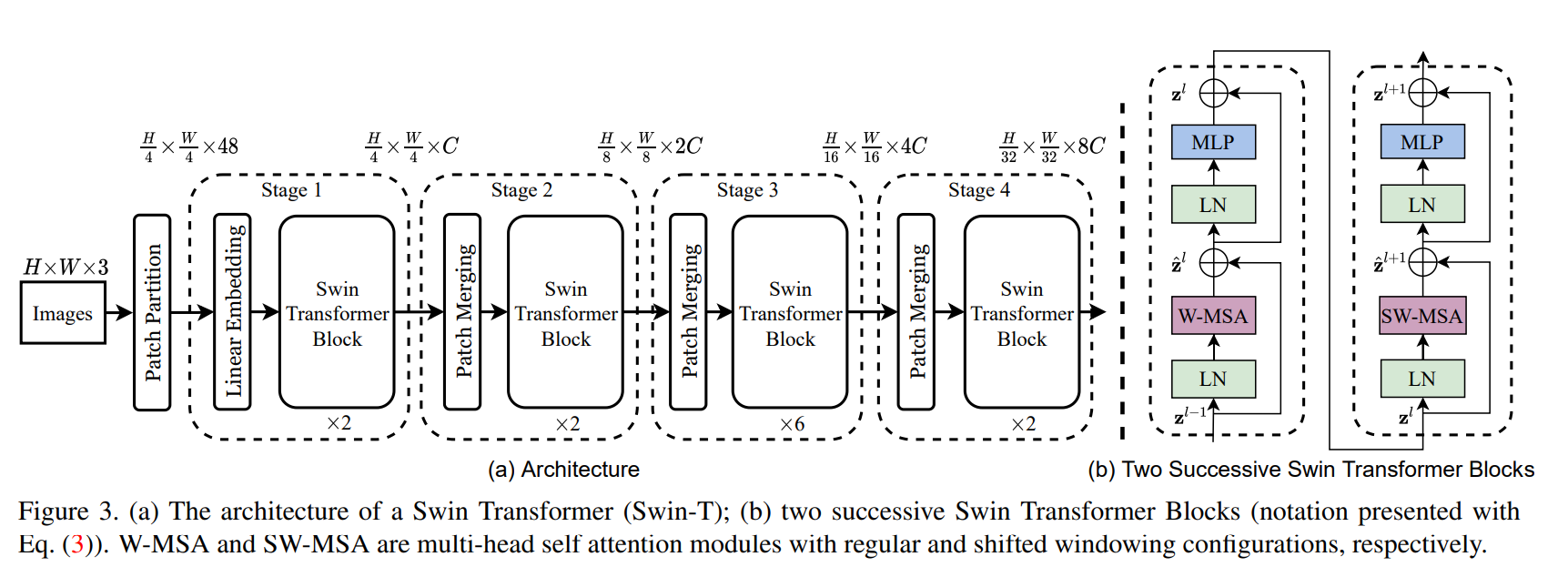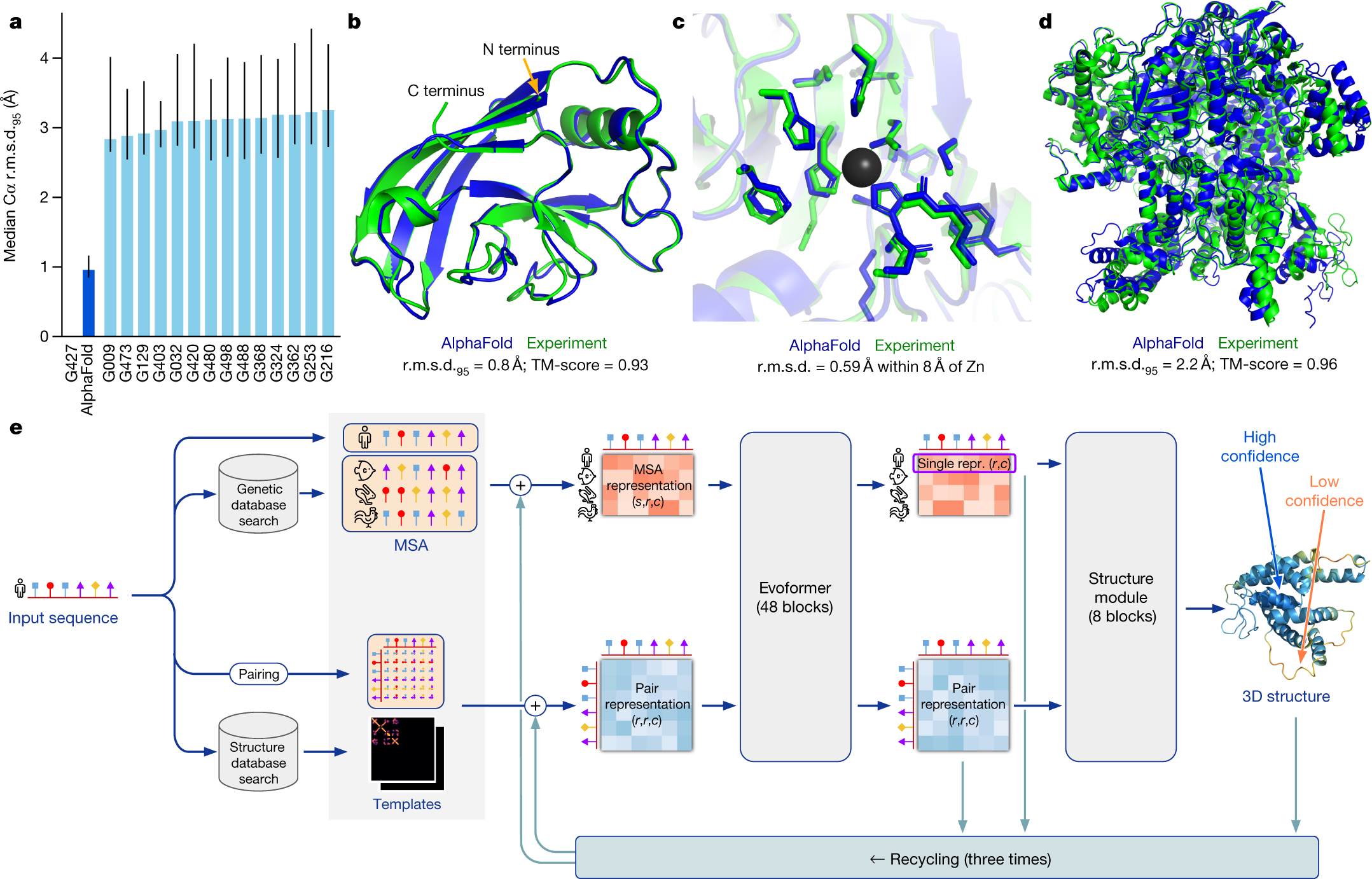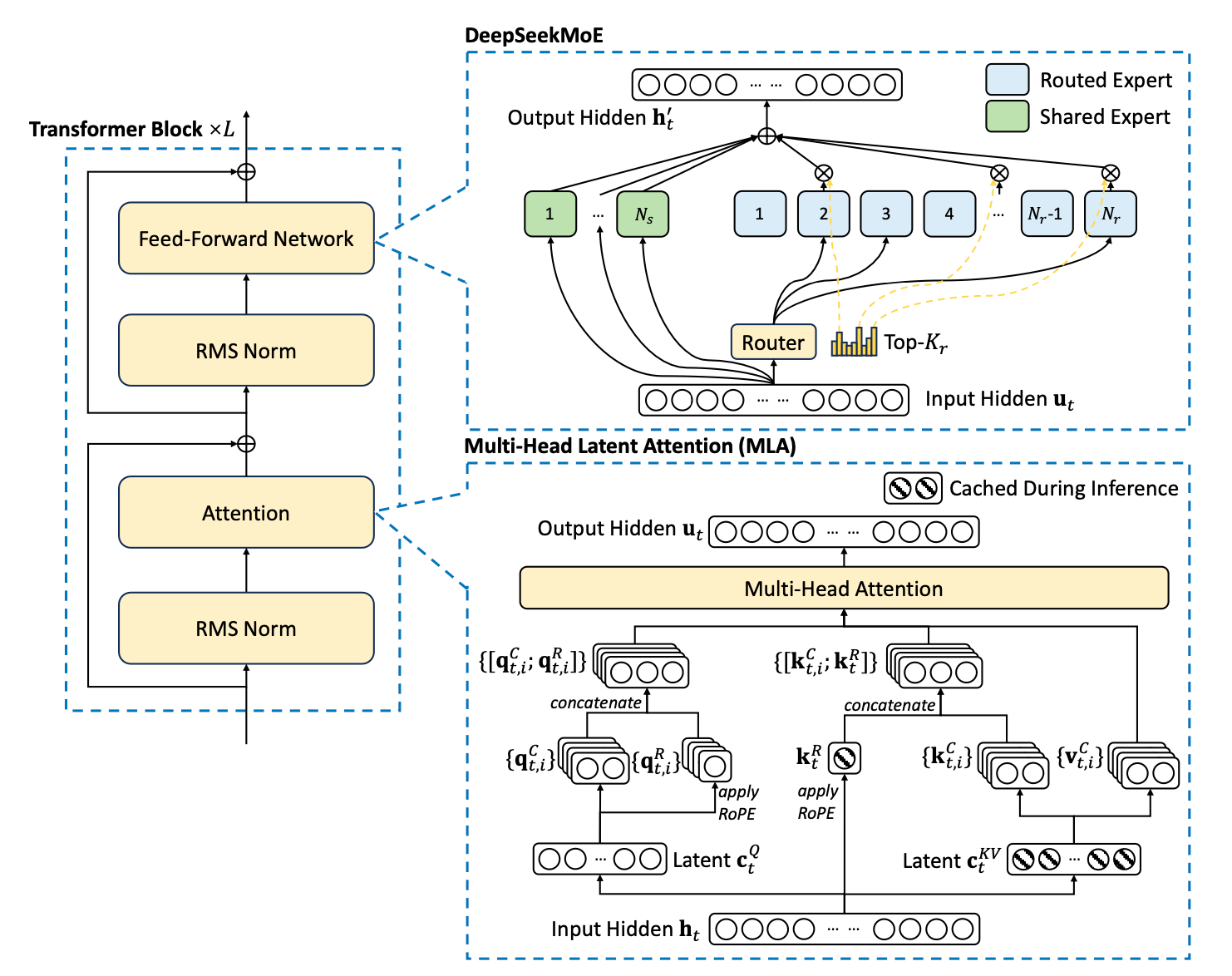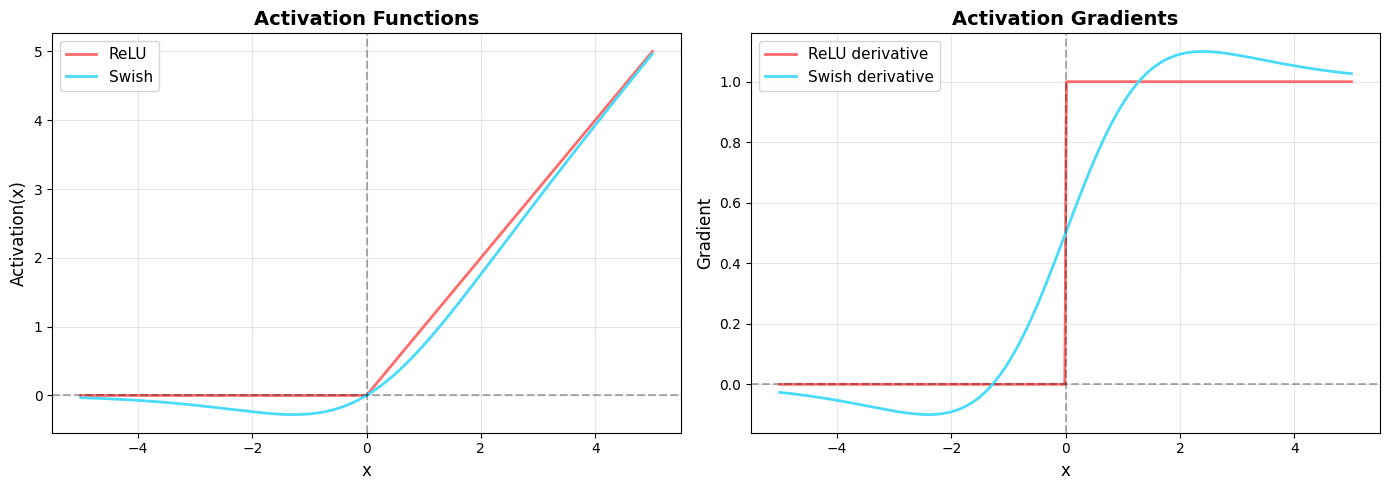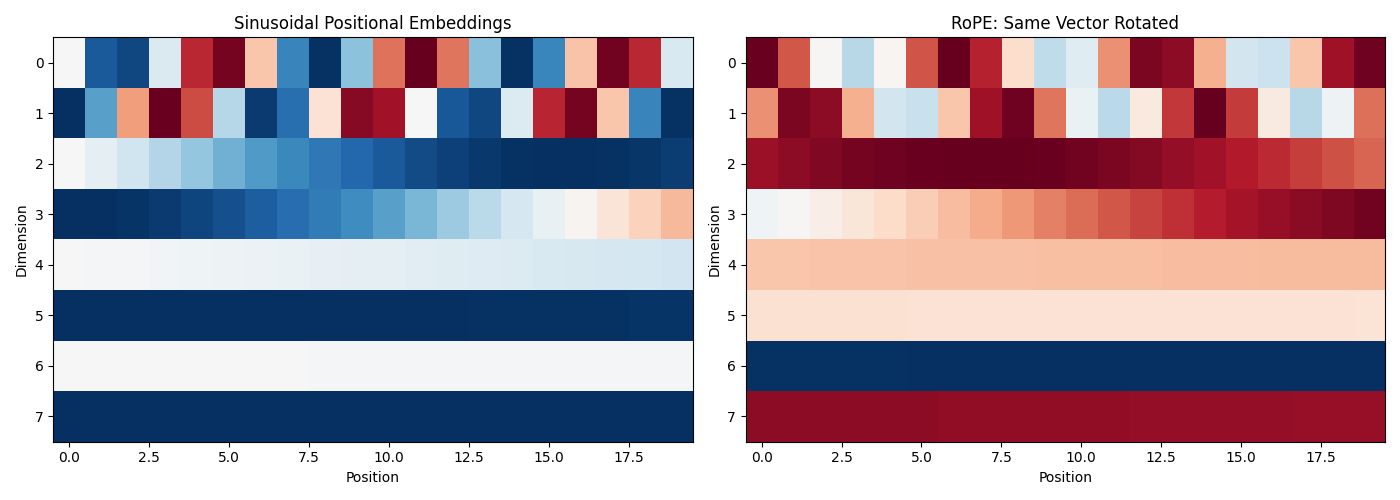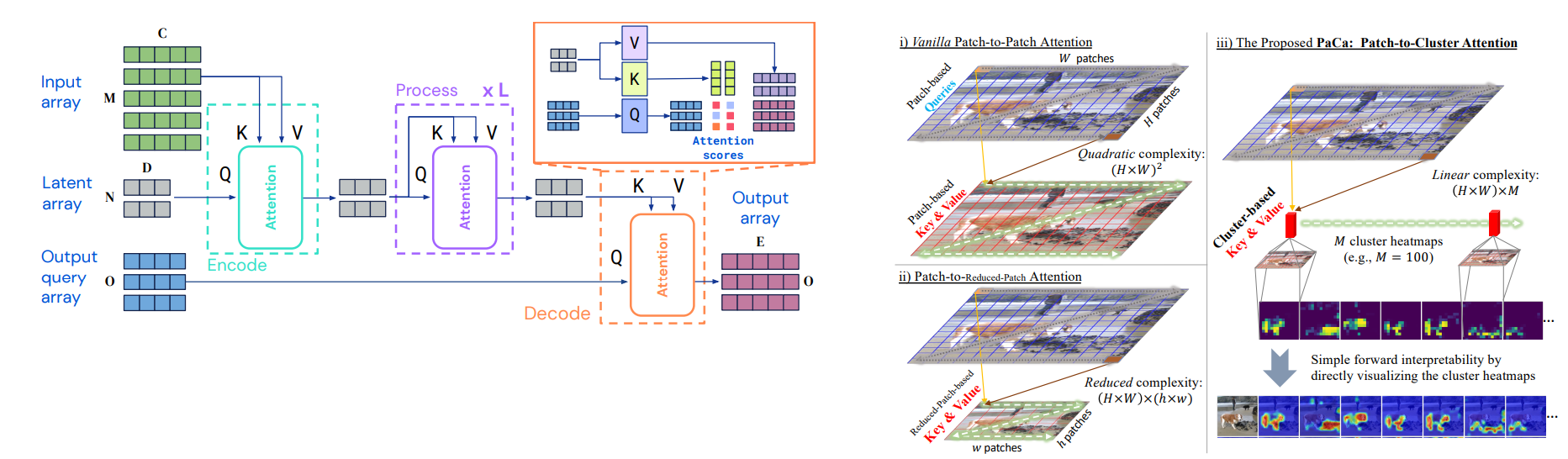
Taming the Transformer: How Perceiver IO and PaCa-ViT Conquer Quadratic Complexity
A deep dive into two novel architectures, Perceiver IO and PaCa-ViT, that break the O(N^2) barrier in Transformers, enabling them to process massive inputs efficiently.