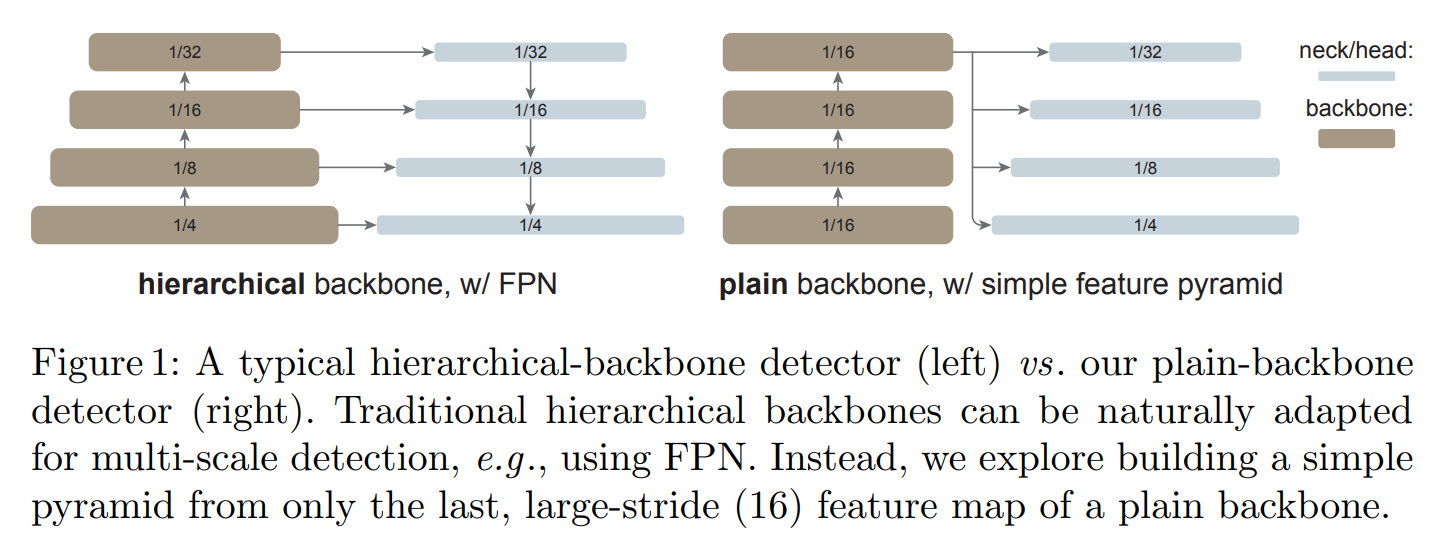
ViTDet: Plain Vision Transformer Backbones for Object Detection
ViTDet demonstrates that plain, non-hierarchical Vision Transformers can compete with hierarchical backbones for object detection through simple adaptations.
ViTDet demonstrates that plain, non-hierarchical Vision Transformers can compete with hierarchical backbones for object detection through simple adaptations.
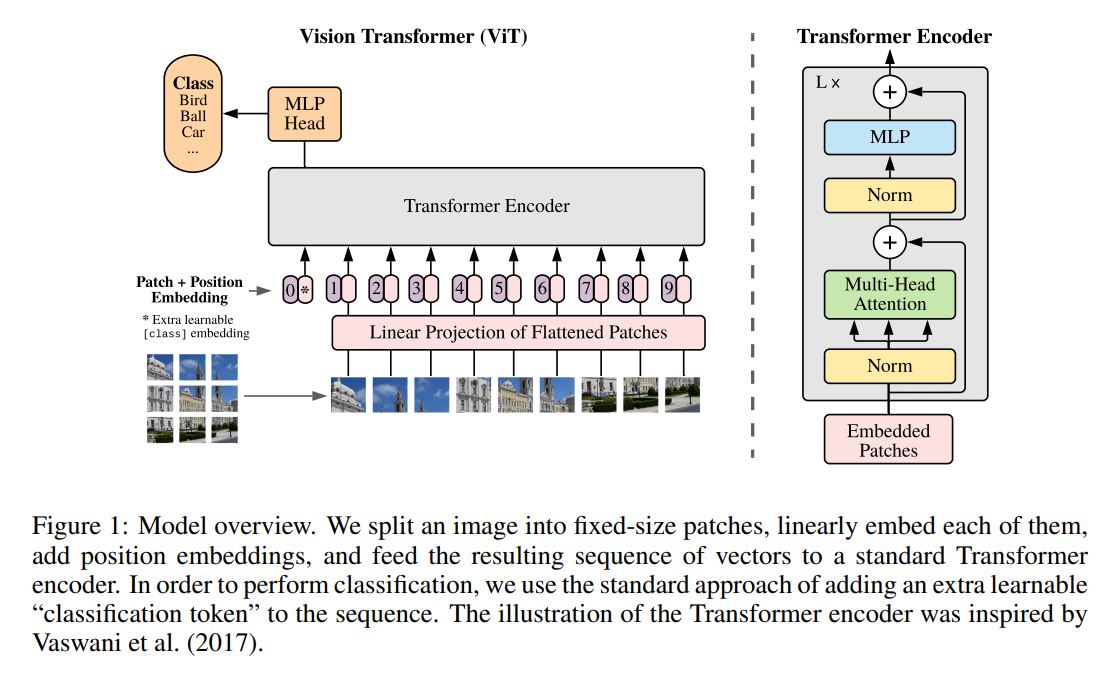
An in-depth look at ‘An Image is Worth 16x16 Words,’ the paper that introduced the pure Vision Transformer, its architecture, novelty, limitations, and how modern models like Swin Transformer evolved from it.